嵌套循环连接(Nested Loop Join)
循环嵌套连接是最基本的连接,正如其名所示那样,需要进行循环嵌套,嵌套循环是三种方式中唯一支持不等式连接的方式,这种连接方式的过程可以简单的用下图展示:

图1.循环嵌套连接的第一步
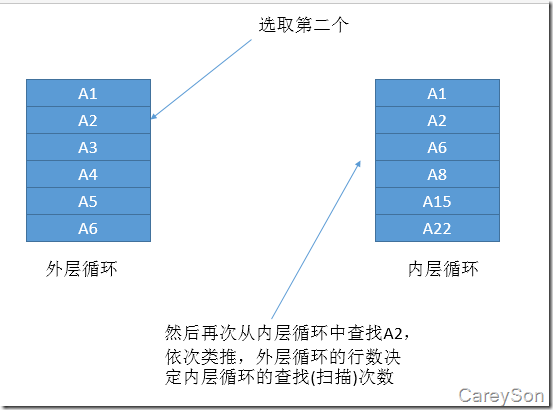
图2.循环嵌套连接的第二步
由上面两个图不难看出,循环嵌套连接查找内部循环表的次数等于外部循环的行数,当外部循环没有更多的行时,循环嵌套结束。另外,还可以看出,这种连接方式需要内部循环的表有序(也就是有索引),并且外部循环表的行数要小于内部循环的行数,否则查询分析器就更倾向于Hash Join(会在本文后面讲到)。通过嵌套循环连接也可以看出,随着数据量的增长这种方式对性能的消耗将呈现出指数级别的增长,所以数据量到一定程度时,查询分析器往往就会采用这种方式。
下面我们通过例子来看一下循环嵌套连接,利用微软的AdventureWorks数据库:

图3.一个简单的嵌套循环连接
图3中ProductID是有索引的,并且在循环的外部表中(Product表)符合ProductID=870的行有4688条,因此,对应的SalesOrderDetail表需要查找4688次。让我们在上面的查询中再考虑另外一个例子,如图4所示。

图4.额外的列带来的额外的书签查找
由图4中可以看出,由于多选择了一个UnitPrice列,导致了连接的索引无法覆盖所求查询,必须通过书签查找来进行,这也是为什么我们要养成只Select需要的列的好习惯,为了解决上面的问题,我们既可以用覆盖索引,也可以减少所需的列来避免书签查找。另外,上面符合ProductID的行仅仅只有5条,所以查询分析器会选择书签查找,假如我们将符合条件的行进行增大,查询分析器会倾向于表扫描(通常来说达到表中行数的1%以上往往就会进行table scan而不是书签查找,但这并不绝对),如图5所示。

图5.查询分析器选择了表扫描
可以看出,查询分析器此时选择了表扫描来进行连接,这种方式效率要低下很多,因此好的覆盖索引和Select *都是需要注意的地方。另外,上面情况即使涉及到表扫描,依然是比较理想的情况,更糟糕的情况是使用多个不等式作为连接时,查询分析器即使知道每一个列的统计分布,但却不知道几个条件的联合分布,从而产生错误的执行计划,如图6所示。

图6.由于无法预估联合分布,导致的偏差
由图6中,我们可以看出,估计的行数和实际的行数存在巨大的偏差,从而应该使用表扫描但查询分析器选择了书签查找,这种情况对性能的影响将会比表扫描更加巨大。具体大到什么程度呢?我们可以通过强制表扫描和查询分析器的默认计划进行比对,如图7所示。

图7.强制表扫描性能反而更好
合并连接(Merge Join)
谈到合并连接,我突然想起在西雅图参加SQL Pass峰会晚上酒吧排队点酒,由于我和另外一哥们站错了位置,貌似我们两个在插队一样,我赶紧说:I'm sorry,i thought here is end of line。对方无不幽默的说:”It's OK,In SQL Server,We called it merge join”。
由上面的小故事不难看出,Merge Join其实上就是将两个有序队列进行连接,需要两端都已经有序,所以不必像Loop Join那样不断的查找循环内部的表。其次,Merge Join需要表连接条件中至少有一个等号查询分析器才会去选择Merge Join。
Merge Join的过程我们可以简单用下面图进行描述:

图8.Merge Join第一步
Merge Join首先从两个输入集合中各取第一行,如果匹配,则返回匹配行。加入两行不匹配,则有较小值的输入集合+1,如图9所示。

图9.更小值的输入集合向下进1
用C#代码表示Merge Join的话如代码1所示。
复制代码 代码如下:public class MergeJoin
{
// Assume that left and right are already sorted
public static Relation Sort(Relation left, Relation right)
{
Relation output = new Relation();
while (!left.IsPastEnd() && !right.IsPastEnd())
{
if (left.Key == right.Key)
{
output.Add(left.Key);
left.Advance();
right.Advance();
}
else if (left.Key < right.Key)
left.Advance();
else //(left.Key > right.Key)
right.Advance();
}
return output;
}
}
代码1.Merge Join的C#代码表示
因此,通常来说Merge Join如果输入两端有序,则Merge Join效率会非常高,但是如果需要使用显式Sort来保证有序实现Merge Join的话,那么Hash Join将会是效率更高的选择。但是也有一种例外,那就是查询中存在order by,group by,distinct等可能导致查询分析器不得不进行显式排序,那么对于查询分析器来说,反正都已经进行显式Sort了,何不一石二鸟的直接利用Sort后的结果进行成本更小的MERGE JOIN?在这种情况下,Merge Join将会是更好的选择。
另外,我们可以由Merge Join的原理看出,当连接条件为不等式(但不包括!=),比如说> < >=等方式时,Merge Join有着更好的效率。
下面我们来看一个简单的Merge Join,这个Merge Join是由聚集索引和非聚集索引来保证Merge Join的两端有序,如图10所示。

图10.由聚集索引和非聚集索引保证输入两端有序
当然,当Order By,Group By时查询分析器不得不用显式Sort,从而可以一箭双雕时,也会选择Merge Join而不是Hash Join,如图11所示。

图11.一箭双雕的Merge Join
哈希匹配(Hash Join)哈希匹配连接相对前面两种方式更加复杂一些,但是哈希匹配对于大量数据,并且无序的情况下性能均好于Merge Join和Loop Join。对于连接列没有排序的情况下(也就是没有索引),查询分析器会倾向于使用Hash Join。
哈希匹配分为两个阶段,分别为生成和探测阶段,首先是生成阶段,第一阶段生成阶段具体的过程可以如图12所示。

图12.哈希匹配的第一阶段
图12中,将输入源中的每一个条目经过散列函数的计算都放到不同的Hash Bucket中,其中Hash Function的选择和Hash Bucket的数量都是黑盒,微软并没有公布具体的算法,但我相信已经是非常好的算法了。另外在Hash Bucket之内的条目是无序的。通常来讲,查询优化器都会使用连接两端中比较小的哪个输入集来作为第一阶段的输入源。
接下来是探测阶段,对于另一个输入集合,同样针对每一行进行散列函数,确定其所应在的Hash Bucket,在针对这行和对应Hash Bucket中的每一行进行匹配,如果匹配则返回对应的行。
通过了解哈希匹配的原理不难看出,哈希匹配涉及到散列函数,所以对CPU的消耗会非常高,此外,在Hash Bucket中的行是无序的,所以输出结果也是无序的。图13是一个典型的哈希匹配,其中查询分析器使用了表数据量比较小的Product表作为生成,而使用数据量大的SalesOrderDetail表作为探测。

图13.一个典型的哈希匹配连接
上面的情况都是内存可以容纳下生成阶段所需的内存,如果内存吃紧,则还会涉及到Grace哈希匹配和递归哈希匹配,这就可能会用到TempDB从而吃掉大量的IO。这里就不细说了,有兴趣的同学可以移步:http://msdn.microsoft.com/zh-cn/library/aa178403(v=SQL.80).aspx。总结
下面我们通过一个表格简单总结这几种连接方式的消耗和使用场景:
嵌套循环连接 合并连接 哈希连接 适用场景 外层循环小,内存循环条件列有序 输入两端都有序 数据量大,且没有索引 CPU 低 低(如果没有显式排序) 高 内存 低 低(如果没有显式排序) 高 IO 可能高可能低 低 可能高可能低
理解SQL Server这几种物理连接方式对于性能调优来说必不可少,很多时候当筛选条件多表连接多时,查询分析器就可能不是那么智能了,因此理解这几种连接方式对于定位问题变得尤为重要。此外,我们也可以通过从业务角度减少查询范围来减少低下性能连接的可能性。
参考文献:
http://msdn.microsoft.com/zh-cn/library/aa178403(v=SQL.80).aspx
http://www.dbsophic.com/SQL-Server-Articles/physical-join-operators-merge-operator.html
文章来自:http://www.cnblogs.com/CareySon/
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
3月27日消息,苹果宣布2024年全球开发者大会(WWDC)将于6月10日至6月14日举行,巧合的是,这次大会与端午假期重合。
苹果官方表示:
在线参加 Apple 每年规模最大的开发者盛会。亲眼见证 Apple 最新平台、技术和工具的发布。了解如何创建和改进你的 App 和游戏。与 Apple 设计师和工程师互动交流,与全球开发者社区建立联系。以上活动均免费在线举行。
探索各种新的工具、框架和功能,助力你打造出理想的 App 和游戏。通过视频讲座学习新技能,与 Apple 专家进行一对一会面,以推进你的项目,完善你的构思。
Swift Student Challenge 旨在支持和鼓舞下一代开发者、创作者和企业家。太平洋时间 3 月 28 日,我们将公布今年的获奖者名单。获奖者将有资格参加在 Apple Park 举办的特别活动。我们还会选出 50 名杰出获胜者,他们将受邀前往库比提诺,获得为期三天的非凡体验,包括参加 Apple Park 的特别活动。
RTX 5090要首发 性能要翻倍!三星展示GDDR7显存
三星在GTC上展示了专为下一代游戏GPU设计的GDDR7内存。
首次推出的GDDR7内存模块密度为16GB,每个模块容量为2GB。其速度预设为32 Gbps(PAM3),但也可以降至28 Gbps,以提高产量和初始阶段的整体性能和成本效益。
据三星表示,GDDR7内存的能效将提高20%,同时工作电压仅为1.1V,低于标准的1.2V。通过采用更新的封装材料和优化的电路设计,使得在高速运行时的发热量降低,GDDR7的热阻比GDDR6降低了70%。
更新日志
- 群星《歌手2024 第13期》[FLAC/分轨][325.93MB]
- 阿木乃《爱情买卖》DTS-ES【NRG镜像】
- 江蕾《爱是这样甜》DTS-WAV
- VA-Hair(OriginalBroadwayCastRecording)(1968)(PBTHAL24-96FLAC)
- 博主分享《美末2RE》PS5 Pro运行画面 玩家仍不买账
- 《双城之战2》超多新歌MV发布:林肯公园再次献声
- 群星《说唱梦工厂 第11期》[320K/MP3][63.25MB]
- 群星《说唱梦工厂 第11期》[FLAC/分轨][343.07MB]
- 群星《闪光的夏天 第5期》[320K/MP3][79.35MB]
- 秀兰玛雅.1999-友情人【大旗】【WAV+CUE】
- 小米.2020-我想在城市里当一个乡下人【滚石】【FLAC分轨】
- 齐豫.2003-THE.UNHEARD.OF.CHYI.3CD【苏活音乐】【WAV+CUE】
- 黄乙玲1986-讲什么山盟海誓[日本东芝版][WAV+CUE]
- 曾庆瑜1991-柔情陷阱[台湾派森东芝版][WAV+CUE]
- 陈建江《享受男声》DTS-ES6.1【WAV】